Подпишитесь, чтобы получать новые статьи
ПодписатьсяВ рамках данной статьи проводится исследование самых популярных ETL-инструментов в Yandex Data Platform. Аббревиатура ETL расшифровывается как Extract, Transform, Load – в дословном переводе это означает: «Извлечение, Преобразование, Загрузка». Является одним из основных процессов при построении архитектуры хранилищ данных, который заключается в том, что сперва производится извлечение данных из внешних источников, затем происходит трансформация и очистка, чтобы соответствовать потребностям бизнес-модели и только потом производится загрузка в DWH (Data Warehouse) для дальнейшего использования в BI-решениях и других прикладных системах. Инфраструктура Yandex Cloud предоставляет большое количество инструментов для ETL и подготовки данных, чтобы в последствии использовать их для анализа и визуализации в Yandex DataLens. 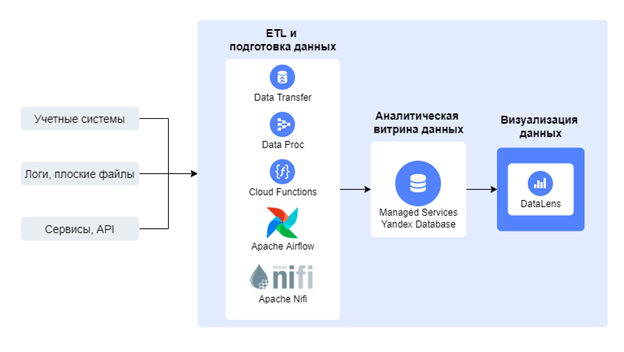 Рис. 1. Концептуальная архитектура подключения к DataLens
Рис. 1. Концептуальная архитектура подключения к DataLens
Давайте рассмотрим каждый из этих популярных ETL-инструментов.
Инструменты для ETL и подготовки данных в экосистеме Yandex Cloud.
Data Transfer – сервис для логического переноса данных из источников в приемники: между СУБД, документоориентированными базами, объектными хранилищами и брокерами сообщений. Механизм транспортировки данных может быть реализован одним из трех типов трансферов:
- Копирование или snapshot (от англ. snapshot — моментальный снимок файловой системы) – первичное создание дубликатов БД на данный момент
- Репликация — перенос только лишь вновь добавленных или отредактированных данных в БД
- Копирование и репликация — первичное создание копии всей БД и затем ее наполнение новыми или измененными данными
Основными преимуществами Yandex Data Transfer:
- Быстрая и интуитивно понятная настройка
- Один надежный сервис для большого количества задач (таких как миграция однородных бд, экспорт данных, организация аналитики и процесса разработки)
- Централизованный сбор необходимых данных из различных баз в единую БД
- Бесплатный сервис
- Регулярно обновляемый и расширяющийся список сценариев и коннекторов
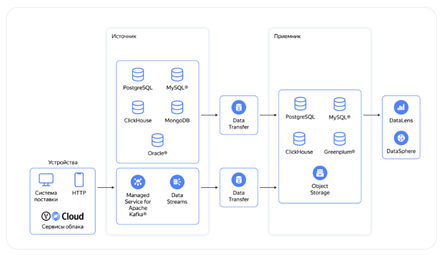 Рис. 2. Коннекторы сервиса Data Transfer с доступными комбинациями источников и приемников
Рис. 2. Коннекторы сервиса Data Transfer с доступными комбинациями источников и приемников
Многозадачный сервис Yandex Data Transfer предназначен для различных целей, таких как:
- Миграция в облако
- Шардирование баз данных или консолидация
- Смена типа хранилища и разделение нагрузки
- Экспорт данных из хранилища клиента в объектное хранилище (например, для удешевления хранения истории изменения данных)
Однако основная цель заключается в трансфере из множества различных источников в единый кластер, например, ClickHouse, для дальнейшего анализа данных в сервисах DataLens или DataSphere.В данном случае особенность заключается в том, что на этапе миграции Data Transfer выполняет роль транспорта, то есть сначала производится snapshot, а затем репликации изменений между большим количеством источников данных, которые могут находиться как в облачном хранилище, так и в локальном.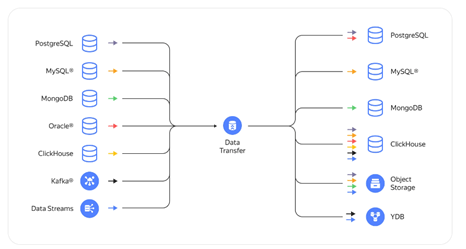 Рис. 3. Архитектура переноса данных из источников в приемники по средствам Data Transfer для дальнейшего анализа данных
Рис. 3. Архитектура переноса данных из источников в приемники по средствам Data Transfer для дальнейшего анализа данных
Data Proc – готовые кластера для экономичной обработки многотерабайтных массивов данных с использованием инструментов с открытым исходным кодом. Data Proc: Apache Spark может обращаться к различным источникам, собирать и обогащать данные и транслировать для дальнейшего хранения, обработки и анализа с помощью сервисов экосистемы Yandex.Yandex Data Proc является серьезным и насыщенным инструментом для сложных архитектурных решений, благодаря совместному использованию широкого функционала набора приложений Apache с открытым исходным кодом: Spark™, Hadoop®, HBase, Hive, Zeppelin, Oozie™, HDFS, YARN, Sqoop™, Flume™, Tez®.Yandex Data Proc: Apache Spark™ выделяется рядом преимуществ:
- Автомасштабируемые Compute-подкластеры на основе показателей загруженности процессоров
- Полный контроль над кластером с root-пользователем для каждой виртуальной машины
- Бесперебойное хранение данных, благодаря автоматической перенастройке неисправных узлов и перераспределению нагрузки
- Широкие возможности распределения прав доступа, которыми управляете только вы
- Встроенная поддержка Apache Airflow 2 (см. страницу 5)
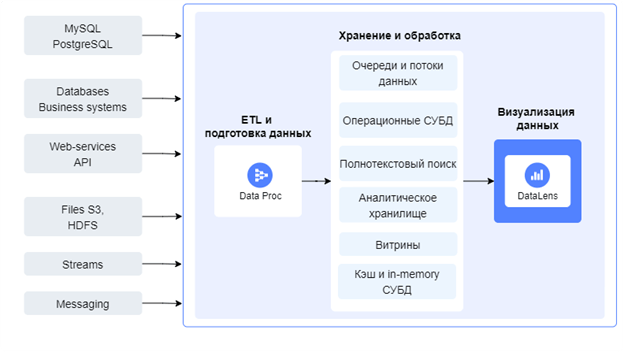 Рис. 4. Архитектура переноса и подготовки данных по средствам Data Proc
Рис. 4. Архитектура переноса и подготовки данных по средствам Data Proc
Cloud Functions – сервис, который позволяет запускать ваш код на любом популярном языке программирования (например, Python, Node.js, Bash, Go и PHP), в виде функции для обработки внешних запросов и отправки ответов без создания и обслуживания виртуальных машин. Платформа функций запускает код пользователя только в том случае, когда приходят внешние запросы в простаивающую функцию, или когда требуется масштабирование при росте нагрузки, что производится автоматически. На этапе сборки Yandex Cloud Functions последовательно сам устанавливает зависимости, которые необходимы для корректной работы функции, что упрощает одновременную работу с несколькими объектами.
Перечислим некоторые возможности и преимущества сервиса Yandex Cloud Functions:
- Бессерверные вычисления позволяют запускать приложения без создания, настройки и обслуживания виртуальной машины
- Идеальный сервис для гибкого масштабирования, так как при увеличении количества вызовов автоматически создаются дополнительные экземпляры вашей функции, которые впоследствии выполняются параллельно
- Очень быстрое развертывание полностью подготовленного рабочего окружения для запуска программ
- Различные популярные языки программирования можно использовать для описания функций
- Бесплатный сервис, если количество вызовов функций не превышает 1 000 000
- Автоматизированная работа с сервисами Yandex Cloud с помощью триггеров
Apache Airflow – сервис, который выполняет функции планирования, создания, исполнения, обработки, мониторинга и дальнейшей трансляции данных в базу данных. Самым частым сценарием использования решения является получение данных из множества различных источников (SQL Server, PostgreSQL, различные API приложений и даже 1С), обработка и подготовка этих данных и затем трансляция этих данных в единое хранилище (например, базу данных ClickHouse для целей дальнейшей аналитики). Он решает распространенную проблему, возникающую в командах по работе с большими данными, связанную с объединением связанных заданий в непрерывный рабочий процесс. Airflow можно использовать практически для всех видов данных, и существует множество различных задокументированных случаев использования, наиболее распространенными из которых являются проекты, связанные с большими данными.В Apache Airflow 2 встроен оператор, поддерживающий провайдер для Yandex Data Proc. Airflow позволяет экономить время на управлении ETL-процессами, построении различных вычислительных pipelines для обучения и разработки моделей в сфере больших данных, а также на описании других итерационных задач.
Основные преимущества Apache Airflow:
- Гибкий и надежный
- Удобный и интуитивно понятный пользовательский интерфейс, что упрощает задачи управления процессом работы с данными
- Простая вставка собственного кода для кастомизации на любом этапе процесса
- Грамотная работа выполнения и контроля настроенных задач
- Неограниченная расширяемость, включая дополнительные плагины и масштабируемость решения и объема обрабатываемых данных
- Легкое разворачивание, интеграция и настройка на облачном сервере
Apache Nifi– это простая платформа обработки событий (сообщений), предоставляющая возможности управления потоками данных из разнообразных источников в режиме реального времени с использованием графического интерфейса. Это современный open source ETL-инструмент. Распределенная архитектура для быстрой параллельной загрузки и обработки данных, большое количество плагинов для источников и преобразований, версионирование конфигураций – это только часть его преимуществ. При всей своей мощи NiFi остается достаточно простым в использовании.Apache NiFi позволяет реализовать как процессы извлечения-трансформации-загрузки (ETL) данных, так и процессы извлечения-загрузки данных (ELT).Существуют два способа реализации подключения Apache Nifi к экосистеме Yandex Data Platform:
- Развертывание сервиса на ресурсах локальной машины и выгрузка данных в Yandex Cloud
- Развертывание Apache Nifi на отдельной виртуальной машине в Yandex Cloud с последующей загрузкой данных в СУБД
Apache Nifi состоит из веб-сервера, контроллера потока и процессора, который работает на виртуальной машине Java. В базовой коробке имеется более 300 процессоров с различными функциональными возможностями, что способствует созданию выходного потокового файла.Основные базовые возможности Apache Nifi:
- Получение данных из различных источников (например, HTTP, различные базы данных, которые поддерживают ODBC/JDBC, файлы и т.д.)
- Широкие возможности произведения преобразований данных
- Разбиение одного потока на несколько в разные системы
- Окончательная выгрузка данных
Однако на каждом этапе работы сервиса есть возможность расширения функциональной составляющей с помощью написания кода на различных языках программирования (Groovy, Jython, Javascript, Python и т.д.).Преимуществами Apache NiFi являются:
- Простое использование графического интерфейса для настройки потоков обработки данных
- Большое количество преднастроенных процессоров (см. далее) для извлечения, обработки и загрузки данных
- Неограниченная возможность разработки собственных процессоров на языке Python
- Поддержка любых форматов данных – структурированных, полуструктурированных, неструктурированных
Таким образом, мы рассмотрели самые популярные ETL-инструменты, которые используются в Yandex Data Platform. Для целей миграции данных из одной БД в другую лучше всего подойдет Data Transfer, в случае простых преобразований лучше всего использовать Cloud Function, для более сложных и объемных ETL процедур наилучшим образом подойдут Apache Airflow/NiFi, а если функционала этих решений недостаточно, то имеет смысл рассмотреть сервис Yandex DataProc с большим объемом различных сервисов, которые помогут решить самую сложную задачу по обработке и подготовке данных.В результате исследования сервисов Yandex Data Platform мы выяснили, что в экосистеме имеются ETL-инструменты почти для любой возможной архитектуры. В данной статье кратко раскрывается основная суть и преимущества каждого ETL-сервиса, у которого есть свои особенности и предназначения, возможности и ограничения. Однако также существует возможность разработки уникальных скриптов, инструментов и коннекторов, например, для интеграции с 1С или другими труднодоступными системами.
При выборе конкретного инструмента для ETL и подготовки данных необходим индивидуальный подход к архитектуре и требуемым критериям каждого клиента. Если вы хотите получить консультацию по различным сценариям и архитектуре в вашем конкретном случае использования ETL-сервисов Yandex или остались какие-либо вопросы по определенному инструменту, обращайтесь к нам в компанию «Ёлва». Наши сотрудники с удовольствием проконсультируют по всем интересующим вопросам и помогут расставить все точки над i.
#DataLens#DataPlatform#Yandex Cloud
Добавить комментарий