Подпишитесь, чтобы получать новые статьи
ПодписатьсяYandex Cloud – это облачная платформа, где каждый может самостоятельно разворачивать и использовать различные элементы цифровой инфраструктуры, такие как управляемы сервисы баз данных, виртуальные машины, сервисы машинного обучения, визуализации данных и многие другие. В этой статье рассмотрим сервисы баз данных в Yandex Cloud.В Yandex Cloud есть возможность развернуть базы данных для различных целей использования. Сервис содержит управляемые сервисы для различных типов хранилищ данных: транзакционных и аналитических баз данных. Каждый сервис предназначен для решения конкретных задач размещения и обработки данных. В случае если вы предполагаете использовать какую-то базу данных, для которой еще нет управляемого сервиса в Yandex Cloud, ее также можно развернуть через сервис виртуальных машин и развернуть необходимые ресурсы на этом стенде. Но, все же, для большинства популярных баз данных в Яндекс Облаке уже есть управляемый сервис, а это означает, что их можно развернуть в два клика, только лишь указав несколько необходимых параметров настройки. Давайте рассмотрим самые распространенные базы данных, которые можно развернуть при помощи управляемого сервиса в Yandex Cloud и определим практическое назначение каждой из них.
Object Storage
Объектное хранилище – это сервис для бюджетного хранения данных в облаке и массовой раздачи данным различным потребителям. В качестве потребителей могут быть другие источники облака (в первую очередь – базы данных), запрос извне (по запросу системы) или прямой доступ пользователем. Объектное хранилище легко встроить в любое приложение для хранения набора исторических и/или неструктурированных данных. Особенностью объектного хранилища является возможность поместить любые файловые данные: бэкапы, фрагменты кода, документы и так далее. Таким образом, объектное хранилище решает две главные задачи: надежное хранение любых типов данных и раздача доступов к этим данным для сколь угодно большого количества пользователей. Например, идеальным применением Object Storage будет видеохостинг, в котором хранится много различных видеоматериалов и доступ к ним нужен одновременно десятку тысяч пользователей.
Данный вид хранилища используется как самый бюджетный способ хранения данных и, в связи с этим может хранить совершенно любые данных, с которыми не проводилось никакой обработки. Для дальнейшей работы с данными, необходима их подготовка в вид табличных баз данных, в первую очередь, реляционных, таких как MySQL и PostgreSQL.
MySQL и PostgreSQL
MySQL – это популярная и широко используемая система СУБД, работающая главным образом на модели реляционных баз данных. Это делает администрирование баз данных более простым и гибким. Проект принадлежит и поддерживается Oracle Corporation.PostgreSQL – это система управления объектно-реляционными базами данных корпоративного класса. Он был разработан в Калифорнийском университете и стал пионером для многих концепций.
На первый взгляд, эти базы данных очень близки друг к другу, но давайте проведем их сравнительных анализ в виде наглядной таблицы.
| Критерий сравнения | MySQL | PostgreSQL |
| Открытый исходный код | Проект MySQL сделал свой исходный код доступным в соответствии с условиями GNU General Public License | PostgreSQL выпускается под своей же лицензией, которая является бесплатной лицензией Open Source |
| Совместимость с SQL | MySQL частично совместим с SQL. Например, он не поддерживается ограничение проверки | PostgreSQL в значительной мере совместим с SQL |
| Поддержка сообщества | Сообщество имеет большое количество участников, которые сосредоточены не только на поддержку существующего функционала, но и на разработку нового. | Активное сообщество постоянно совершенствует существующие функции, а инновационное сообщество стремится обеспечить сохранность PostgreSQL в роли самой передовой базы данных. Обновления функционала и улучшения безопасности регулярно выпускаются. |
| Сценарии использования | Зачастую используется в веб-проектах, которым требуется база данных для записи и хранения простых транзакций данныхХорошо работает в системах OLAP и OLTP, когда требуются только скорости чтения | Широко используется в больших системах, где скорость чтения и записи важнаХорошая производительность при выполнении сложных запросов |
| Поддержка JSON | MySQL имеет поддержку типов данных JSON, но не поддерживает другие функции NoSQL | PostgreSQL поддерживает JSON и другие функции NoSQL, такие как XML. Это также позволяет индексировать данные для более быстрого доступа. |
| Поддержка материализованных представлений | Поддерживает материализованные представления и временные таблицы | Поддерживает временные таблицы, но не предлагает материализованные представления |
Какую же базу данных выбрать?
После сравнения обоих можно сказать, что MySQL проделал большую работу по улучшению себя, чтобы сохранить актуальность, но функциональные возможности PostgreSQL, на сегодняшний день, занимают более лидирующие позиции. Например, PostgreSQL предлагает наследование таблиц, системы правил, возможность реализации пользовательских типов данных и поддерживает функционал событий базы даны. Таким образом, ключевая разница двух систем:• PostgreSQL – это система управления объектами реляционными базами данных, тогда как MySQL – это управляемая сообществом система СУБД.• PostgreSQL поддерживает современные приложения, такие как JSON, XML и другие, в то время как MySQL поддерживает только JSON.• PostgreSQL хорошо работает при выполнении сложных запросов, тогда как MySQL хорошо работает в системах OLAP и OLTP.• PostgreSQL поддерживает материализованные представления, а MySQL нет.

Таким образом, как вы убедились, что при всей схожести двух баз данных, PostgreSQL является более функциональной, относительно MySQL. Также еще одним преимуществом PostgreSQL является высокая возможность масштабирования, ведь при увеличении количества данных и переходе на аналитику больших данных, PostgreSQL заменяется на Greenplum. Проще говоря, Greenplum – это несколько взаимосвязанных экземпляров PostgreSQL, объединенных в кластер по принципу без разделения ресурсов, поэтому в результате перехода мы получаем большие возможности масштабирования нашей базы данных.
Greenplum
Greenplum – это массивно-параллельная СУБД, которая является популярным решение для масштабных аналитических систем. Используется для сложной аналитики по большим объемам данных. Greenplum предлагает понятный пользователям синтаксис ANSI SQL, хорошо ложится на облачный ландшафт, позволяет обучать и применять модели машинного обучения, а еще поддерживает реляционную СУБД PostgreSQL. Благодаря MPP-архитектуре быстро выполняет сложные аналитические запросы и обладает возможностями масштабируемости на десятки терабайт. Используется для целей анализа данных и BI-аналитики, для загрузки хранения структурированных данных и в случаях необходимости использования алгоритмов машинного обучения.
Ключевыми отличиями Greenplum от PostgreSQL являются архитектура и сценарии использования. Greenplum осуществляет массивно-параллельную обработку без разделения ресурсов, а PostgreSQL классическую клиент-серверную. По сценариям использования, Greenplum идеально подходит для обширной OLAP-аналитики больших данных, PostgreSQL – для баз данных небольшого размера с OLTP-кейсами.

Таким образом, Greenplum хорошо оптимизирован под хранение и аналитику больших наборов данных, но в транзакционной середе работает не так хорошо. Однако, PostgreSQL может предложить обработку только одного хоста без разбиения на разделы, сжатия и хранения столбцов. В то время как Greenplum способен обрабатывать данные параллельно в кластере, что увеличивает производительность выполнения запроса и сокращает время отклика от базы данных. Именно поэтому его используют для масштабного анализа данных в OLAP-сценариях.
Yandex Database (YDB)
Yandex Database (YDB) – распределенная отказоустойчивая реляционная система управления базами данных, разработанная в компании Яндекс. YDB можно развернуть как на собственном сервере, так и в составе облачной инфраструктуры. База данных позволяет использовать крупные сервисы, которые способны выдерживать большую операционную нагрузку (до уровня миллионов запросов в секунду). В качестве языка запросов используется YQL (YDB Query Language) – диалект SQL со строгой типизацией. YDB реализовывает распределение транзакции между данными одной или нескольких таблиц. Yandex Database позволяет на своей основе создавать приложения, которые можно быстро масштабировать по нагрузке и по объему данных. Преимуществом базы данных является высокий уровень обеспечения отказоустойчивости: реализованы возможности продолжить работу при отключении одного из дата-центов, а также преимущество в том, что БД в любой момент можно масштабировать на десятки тысяч серверов на чтение и запись.
ClickHouse
ClickHouse также является разработкой компании Яндекс и эта СУБД славится в первую очередь своей быстротой, поэтому очень даже рекомендована для целей аналитики, где требуется получать быстрый ответ на большое количество запросов в один момент времени. По сравнению с СУБД, рассмотренным выше в статье, ClickHouse является колоночной (столбцовой) системой управления базами данных, что позволяет обеспечивать высокую проиводительность даже при большой нагрузке.
Таким образом, при помощи ClickHouse можно решить классическую проблему транзакционных (строковых) баз данных, которая связана с медленной работой аналитических запросов, если количество записей в БД превышает несколько миллиардов строк. Это связано с тем, что при создании отчетов, такого типа СУБД анализируют еще и большое количество лишней связанной информации, к сожалению, в транзакционных СУБД не помогает даже оптимизация. Единственное решение проблемы – это использование колоночной СУБД, такой как ClickHouse.

ClickHouse хранит данные в колонках, поэтому если один столбец содержит единственный набор значений, то становится гораздо проще строить отчеты по каким-либо показателям. Колоночные СУБД лучше всего подходят для OLAP сценариев работы, то есть обработки аналитических запросов в режиме онлайн. Вот некоторые преимущества колоночной базы данных ClickHouse:
• Поскольку база данных является столбцовой, то данные необходимые для аналитики считываются только из нужных колонок, а однотипная информация сжимается.
• Поддержка приближенных вычислений на части выборки помогает снизить число обращения к жесткому диску.
• Сортировка данных производится по первичному ключу.• Векторные вычисления по кусочкам столбцов снижают нагрузку на CPU.• Линейная масштабируемость позволяет увеличивать размеры кластера до очень больших размеров.
• Работа с жесткими дисками – движок обработки запросов ClickHouse устроен таким образом, что данные не попадают в кеш оперативной памяти, что сильно снижает стоимость владения базой данных, так как стоимость памяти на жестком диске сильно ниже, чем оперативной памяти.
ClickHouse поддерживает язык SQL и соответствует PostgreSQL с точки зрения выразительности и простоты. При всех плюсах базы данных для использования в своей инфраструктуре, в первую очередь для аналитики, у ClickHouse есть операции, для которых этот тип базы данных не подойдет вовсе – для хранения неструктурированных данных (таким как видео, картинки, музыка и другие), а также для обновления данных, поскольку ClickHouse не поддерживает транзакции.
Подводя итог, ClickHouse менее универсальная СУБД, чем те, что мы рассмотрели выше, однако она отлично подходит для аналитических задач. Благодаря ее табличной структуре система способна выполнять сразу несколько запросов и при этом не нагружать память кластера, на котором база данных установлена. СУБД ClickHouse чаще всего используется для анализа онлайн-запросов, а также различных мониторингов активности пользователей.
Выводы
В рамках статьи мы рассмотрели 6 различных баз данных, которые можно легко развернуть в Яндекс Облаке, благодаря инструменту управляемых сервисов. Для развертывания необходимой базы данных необходимо заполнить стандартные настройки для соответствующего сервиса и подождать несколько минут, и после этого необходимый вам сервис будет развернут и полностью готов для использования.
По итогу рассмотрения различных баз данных, очевидно, что нет какой-либо универсальной СУБД, которая могла бы одна единственная использоваться для всех целей создания, хранения и обработки данных, каждая из баз данных уникальна и обладает своим набором достоинств и недостатков. Object Storage отлично подходит для хранения неструктурированных данных, а также является самым дешевым вариантов хранения для данных относительно стоимости за единицу памяти. MySQL и PostgreSQL работают со структурированными данными, и позволяет использовать эти базы данных для хранения данных, получаемых из различных систем, когда данных относительно немного. Другое дело, когда данных много, необходимо хранить в единой базе данных исторические данные, а также есть необходимость хранить данные из множества различных систем в едином хранилище, тогда тут на помощь приходят такие базы данных как Greenplum и YDB. А если появляется необходимость в базе данных для использования в целях аналитики (анализа метрик, построения BI-отчетности), то тут наилучшим образом подойдет база данных ClickHouse, благодаря своей колоночной структуре хранения данных и оптимизированным использованием ресурсов при работе с такого рода запросами.
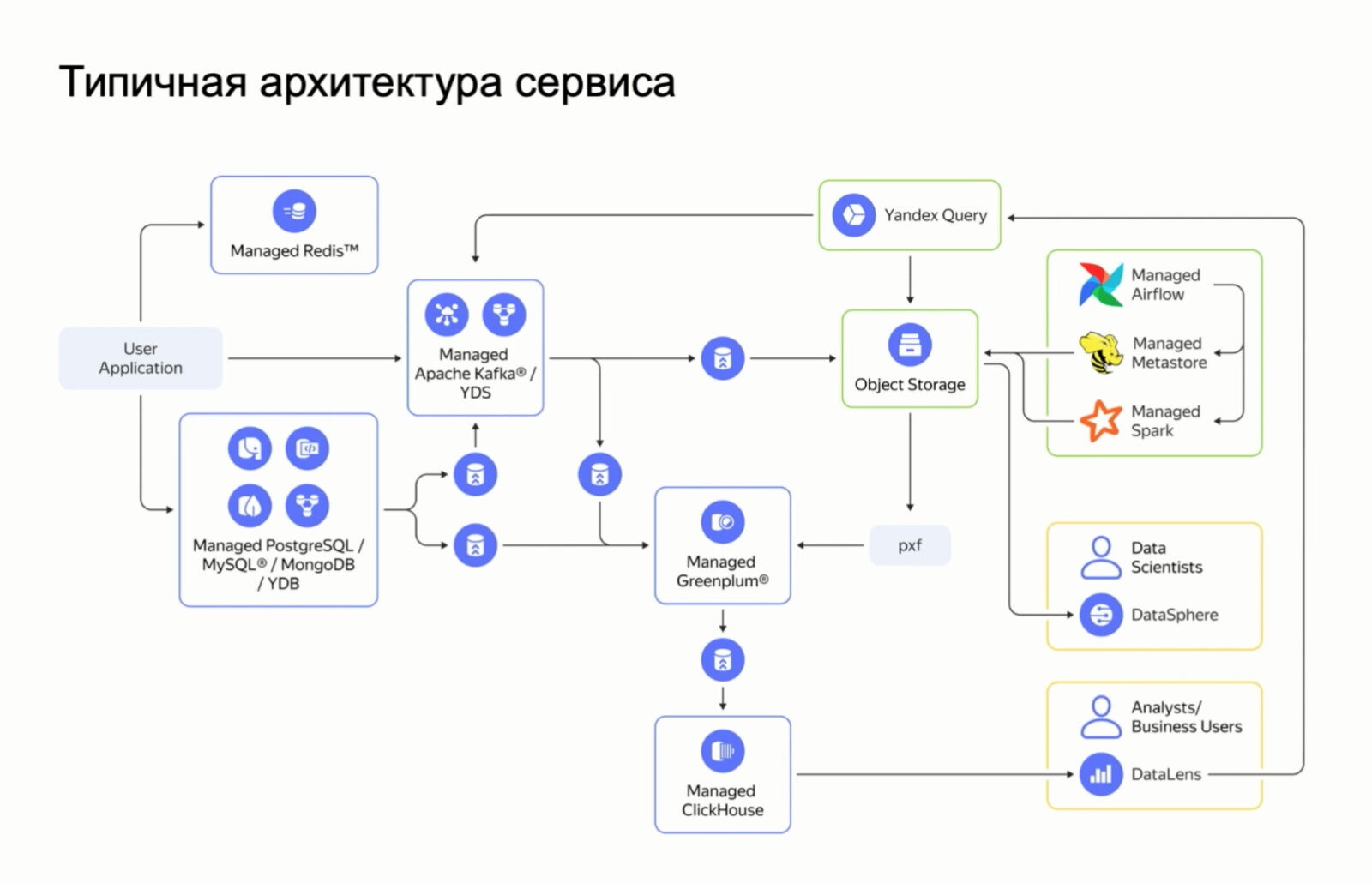
В связи с тем, что каждая база данных уникальная и предполагает свои сценария использования, зачастую в проектах используется несколько различных баз данных, каждая из которых выполняет свою роль. Именно такое одновременное использование образует архитектуру хранения, подготовки и использования данных.
В случае если у вас остались вопросы или вам интересно какую именно архитектуру предпочтительнее использовать для решения вашего кейса, то обращайтесь к нам, в компанию Ёлва, наши специалисты с радостью вас проконсультируют.
#ClickHouse#DB#Greenplum#MySQL#PostgreSQL#Yandex Cloud
Добавить комментарий