
Простота использования
Выберите размер кластера, мощность узлов и набор сервисов, а Data Proc автоматически создаст и настроит кластеры Spark, Hadoop и другие компоненты.
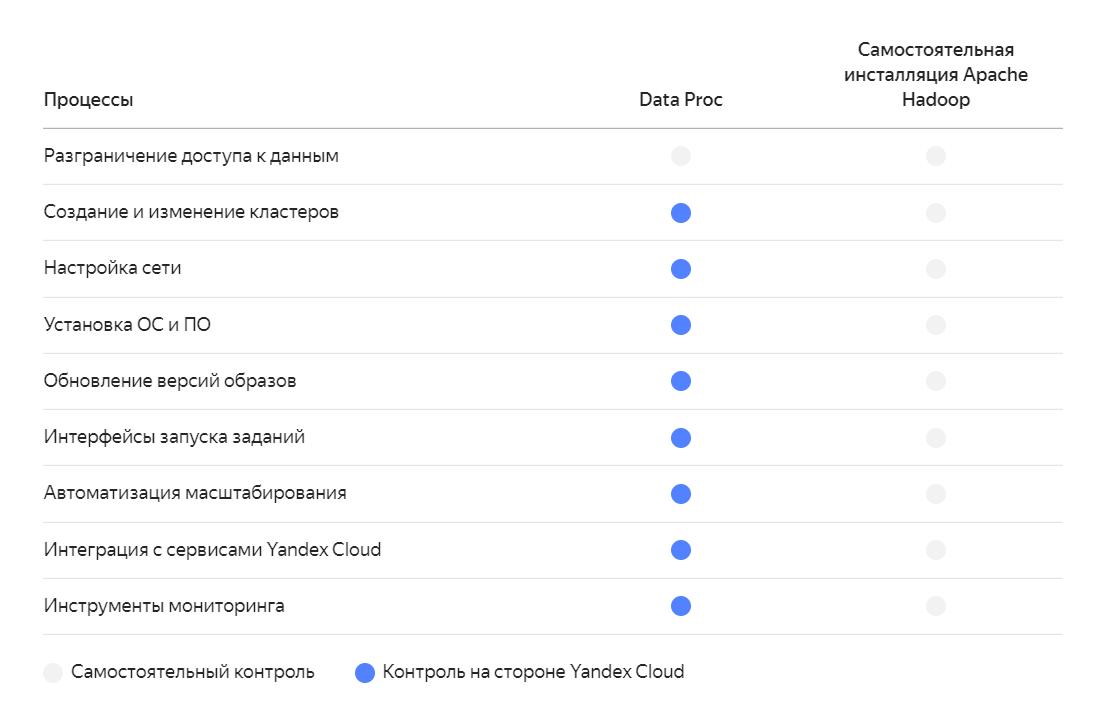
Yandex Data Proc — сервис для обработки многотерабайтных массивов данных с использованием инструментов с открытым исходным кодом, таких как Apache Spark™, Apache Hadoop®, Apache HBase, Apache Hive, Apache Zeppelin и других сервисов экосистемы Apache®.

14 октября, 2022

5 октября, 2022

21 сентября, 2022
21 сентября, 2022

25 августа, 2022

16 августа, 2022
Выберите размер кластера, мощность узлов и набор сервисов, а Data Proc автоматически создаст и настроит кластеры Spark, Hadoop и другие компоненты.
Data Proc использует группы виртуальных машин Instance Groups, чтобы автоматически наращивать или уменьшать вычислительные ресурсы compute-подкластеров на основе показателей загруженности процессоров.
Можно запустить кластер Data Proc, содержащий 10 узлов всего за 18 рублей в час. Еще можно экономить до 70% от стоимости виртуальных машин, выбирая прерываемые виртуальные машины.
Data Proc заменяет вышедшие из строя узлы, перераспределяет нагрузку между ними автоматически и перезапускает задачи.
Устанавливайте собственные приложения и библиотеки на работающих кластерах без необходимости их перезагружать.
Сэкономьте время на построении ETL-пайплайнов и пайплайнов для обучения и разработки моделей, а также для описания других итерационных задач.
Экспертные мнения, свежие новости и решения мира информационных технологий, а также анонсы наших статей и мероприятий.
Просто нажмите кнопку “следовать” ниже и подпишитесь на наш Тг-канал
СЛЕДОВАТЬ